Spatial Clustering
The Spatial Clustering tool creates clustered zones by grouping nearby features into a specified number of spatial clusters.
1. Explanation
The Spatial Clustering tool groups a set of spatial features into a specified number of spatial zones. It offers two clustering methods:
K-Means — A fast, geometry-based method that groups features by proximity to cluster centers. This method does not aim to provide equal-sized zones.
Balanced Zones — A genetic algorithm that creates zones with near-equal sizes, either by feature count or by a numeric field value. This method also supports compactness constraints to limit the spatial spread of each zone.
The Spatial Clustering tool is currently limited to point features only. It only supports a maximum of 2,000 points. For larger datasets, consider pre-filtering or sampling your data before running the tool.
- The Balanced Zones method uses a genetic algorithm which is non-deterministic. Different runs may produce slightly different zone configurations.
- Execution time for Balanced Zones can vary significantly based on the number of points and desired clusters. It is generally slower than K-Means, taking anywhere from 1 Minute to 3 minutes depending on dataset complexity.
2. Example use cases
Dividing sales territories into balanced zones based on customer locations and revenue.
Grouping population locations into areas with equal population size.
Grouping potential car-sharing stations into service areas.
3. How to use the tool?
Toolbox  .
. Geoanalysis menu, click on Spatial Clustering.Input
Input Layer from the drop-down menu. This must be a point layer containing the features you want to cluster.Number of Clusters — the number of zones to create (default: 10).Configuration
Cluster Type.- K-Means
- Balanced Zones
K-Means groups features by proximity to cluster centers. It is fast and suitable when you need a quick spatial grouping without strict size balancing.
No additional configuration is required for K-Means.
Balanced Zones uses a genetic algorithm to create zones with equal or near-equal sizes. This method is slower but produces more balanced results.
Additional configuration options become available:
Size Method: Count for equal features counts per zone, or Field Value to balance by a numeric attribute.Size Field — a numeric field from your input layer to use as the balancing weight.Limit Zone Area to add a compactness constraint. When enabled, configure the Max Distance to limit the maximum distance between two features in the same cluster.Run to start the calculation.Results
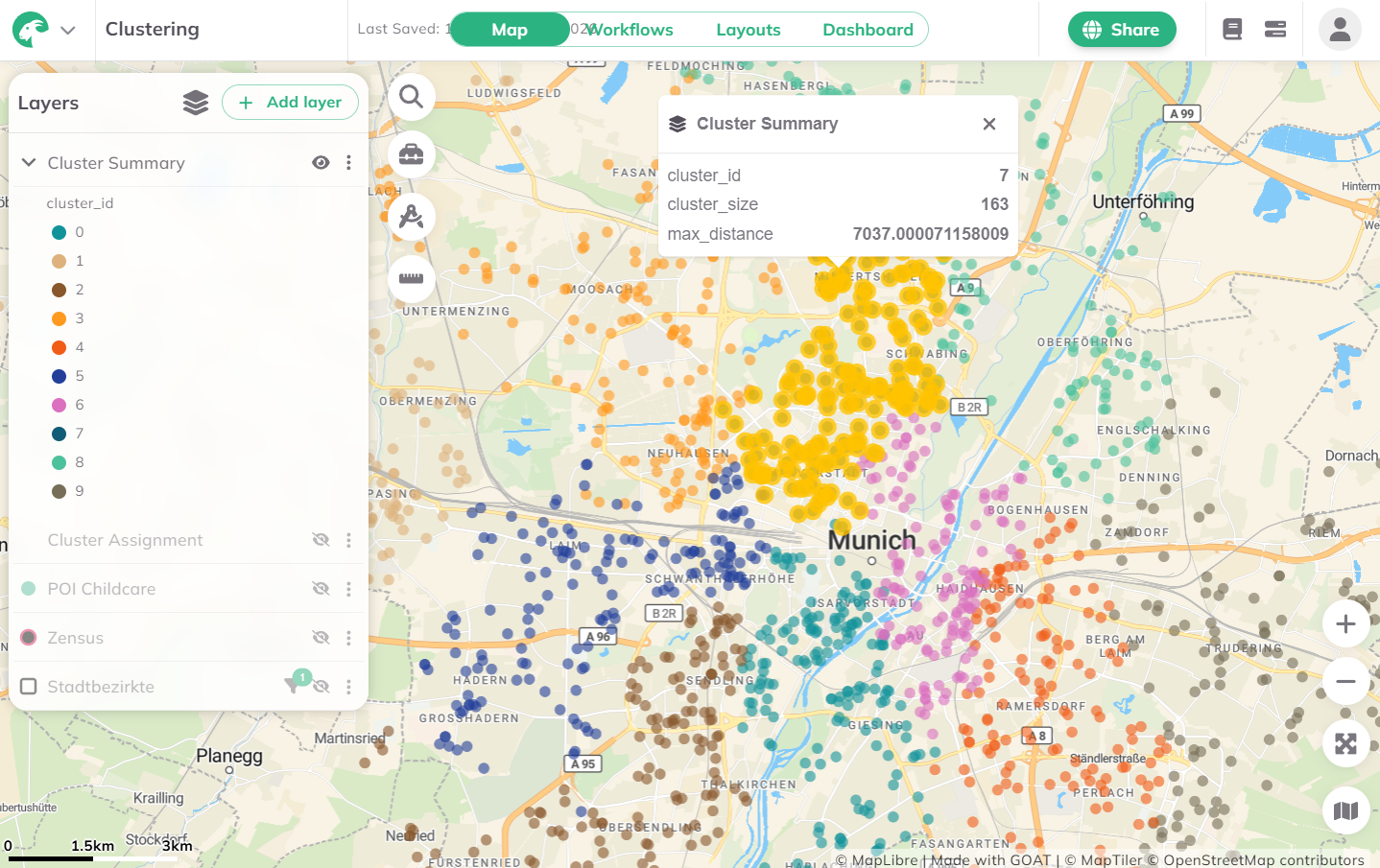
Once the calculation is complete, two result layers will be added to the map:
- Features layer — The original input features, each assigned a
cluster_id. - Summary layer — One multigeometry feature per zone, with zone statistics (size, maximum distance between features).
Want to create visually compelling maps that tell a clear story? Learn how to customize colors, legends, and styling in our Styling section.
4. Technical details
K-Means Clustering
The K-Means algorithm works iteratively:
- Initialization — k initial centroids are chosen using a furthest-point strategy for better spread.
- Assignment — Each feature is assigned to the nearest centroid based on Euclidean distance (in projected coordinates).
- Update — Centroids are recalculated as the mean position of all assigned features.
- Repeat until centroids converge or the maximum number of iterations is reached.
Balanced Zones
The Balanced Zones method uses a genetic algorithm to find optimal spatial groupings:
- An initial population of solutions is created using K-Means as a starting point, plus random variations.
- For each solution, extract seed for each cluster and grow zones through spatial neighbors to assign all features to clusters. Features unassigned by growth are assigned to the smallest surrounding cluster. The frontier features of large clusters can then be reassigned to smaller zones.
- Each solution is scored based on a fitness score.
- The best solutions are combined and mutated across multiple generations to progressively improve the result.
- The algorithm stops when no further improvement is found or the maximum number of generations is reached.
The algorithm uses spatial neighbor graphs to ensure contiguous zone growth — features are assigned to zones through their spatial neighbors, promoting compact and connected clusters.
Fitness function:
Each candidate solution is scored based on:
- Size variance — How evenly the zones are sized (primary objective).
- Compactness penalty (optional) — Penalizes zones where the maximum distance threshold is exceeded.
All constraints (equal size, compactness) are soft constraints — the algorithm optimizes toward them but does not enforce them as hard limits.
Algorithm parameters:
| Parameter | Value | Description |
|---|---|---|
| Population size | 40–50 | Number of candidate solutions per generation |
| Generations | 40–50 | Maximum number of evolutionary cycles |
| Mutation rate | 0.1 | Probability of changing cluster seed location |
| Crossover rate | 0.7 | Probability of combining parent solutions |
| Elitism | Top 10% | Best solutions preserved across generations |
Adaptive parameters: For larger datasets (>500 features), the population size and generation count are automatically reduced to maintain reasonable computation times.