Räumliches Clustering
Das Werkzeug Räumliches Clustering erstellt geclusterte Zonen durch Gruppierung nahegelegener Features in eine angegebene Anzahl räumlicher Cluster.
1. Erklärung
Das Werkzeug Räumliches Clustering gruppiert eine Menge räumlicher Features in eine angegebene Anzahl räumlicher Zonen. Es bietet zwei Clustering-Methoden:
K-Means — Eine schnelle, geometriebasierte Methode, die Features nach Nähe zu Clusterzentren gruppiert. Diese Methode zielt nicht darauf ab, gleich große Zonen bereitzustellen.
Ausgeglichene Zonen — Ein genetischer Algorithmus, der Zonen mit annähernd gleicher Größe erstellt, entweder nach Anzahl der Features oder nach einem numerischen Feldwert. Diese Methode unterstützt auch Kompaktheitseinschränkungen, um die räumliche Ausdehnung jeder Zone zu begrenzen.
Das Werkzeug für räumliches Clustering ist derzeit auf Punkt-Features beschränkt. Es unterstützt maximal 2.000 Punkte. Für größere Datensätze sollten Sie Ihre Daten vor der Ausführung des Werkzeugs filtern oder eine Stichprobe nehmen.
- Die Methode Ausgeglichene Zonen verwendet einen genetischen Algorithmus, der nicht deterministisch ist. Verschiedene Läufe können leicht unterschiedliche Zonenkonfigurationen erzeugen.
- Die Ausführungszeit für Ausgeglichene Zonen kann je nach Anzahl der Punkte und gewünschten Cluster erheblich variieren. Sie ist im Allgemeinen langsamer als K-Means und kann je nach Datensatzkomplexität zwischen 1 Minute und 3 Minuten dauern.
2. Anwendungsfälle
Aufteilung von Verkaufsgebieten in ausgeglichene Zonen basierend auf Kundenstandorten und Umsatz.
Gruppierung von Bevölkerungsstandorten in Gebiete mit gleicher Bevölkerungsgröße.
Gruppierung potenzieller Carsharing-Stationen in Servicebereiche.
3. Vorgehensweise
Werkzeuge  .
. Geoanalyse auf Räumliches Clustering.Eingabe
Eingabe-Layer aus dem Dropdown-Menü. Dies muss ein Punkt-Layer sein, der die zu clusternden Features enthält.Anzahl der Cluster fest – die Anzahl der zu erstellenden Zonen (Standard: 10).Konfiguration
Cluster-Typ.- K-Means
- Ausgeglichene Zonen
K-Means gruppiert Features nach Nähe zu Clusterzentren. Es ist schnell und eignet sich, wenn Sie eine schnelle räumliche Gruppierung ohne strenge Größenbalance benötigen.
Für K-Means ist keine zusätzliche Konfiguration erforderlich.
Ausgeglichene Zonen verwendet einen genetischen Algorithmus, um Zonen mit gleicher oder annähernd gleicher Größe zu erstellen. Diese Methode ist langsamer, liefert aber ausgewogenere Ergebnisse.
Zusätzliche Konfigurationsoptionen werden verfügbar:
Größenmethode: Anzahl für gleiche Feature-Anzahlen pro Zone oder Feldwert, um nach einem numerischen Attribut auszugleichen.Größenfeld – ein numerisches Feld aus Ihrem Eingabe-Layer, das als Ausgleichsgewichtung verwendet wird.Zonengebiet begrenzen, um eine Kompaktheitseinschränkung hinzuzufügen. Wenn aktiviert, konfigurieren Sie die Max. Distanz, um die maximale Entfernung zwischen zwei Features im selben Cluster zu begrenzen.Ausführen, um die Berechnung zu starten.Ergebnisse
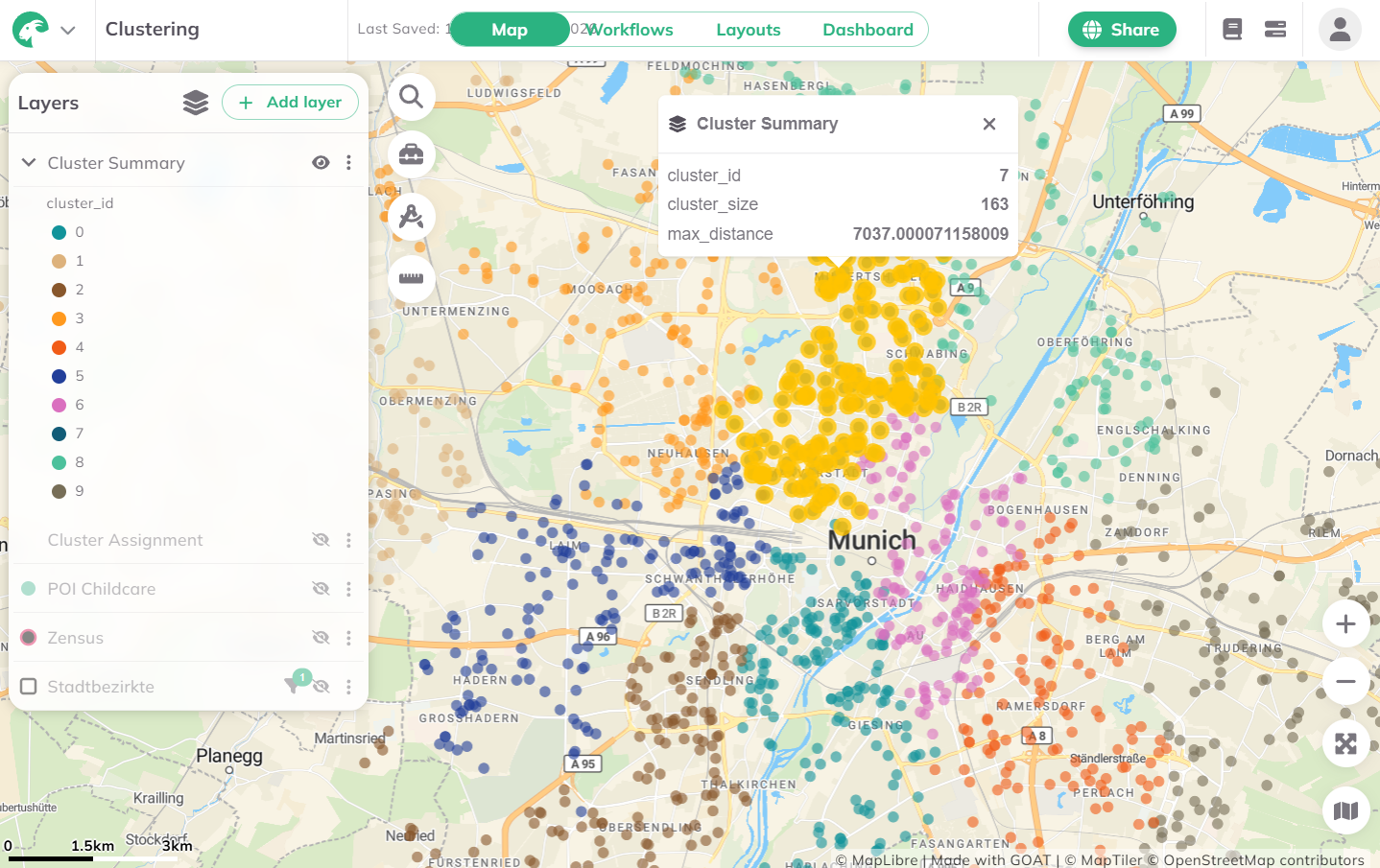
Sobald die Berechnung abgeschlossen ist, werden zwei Ergebnis-Layer zur Karte hinzugefügt:
- Features-Layer — Die ursprünglichen Eingabe-Features, denen jeweils eine
cluster_idzugewiesen wurde. - Zusammenfassungs-Layer — Ein Multigeometrie-Feature pro Zone mit Zonenstatistiken (Größe, maximale Distanz zwischen Features).
Möchten Sie visuell ansprechende Karten erstellen, die eine klare Geschichte erzählen? Erfahren Sie, wie Sie Farben, Legenden und Stile in unserem Abschnitt Styling anpassen können.
4. Technische Details
K-Means Clustering
Der K-Means-Algorithmus arbeitet iterativ:
- Initialisierung — k anfängliche Zentroide werden unter Verwendung einer Furthest-Point-Strategie für eine bessere Verteilung ausgewählt.
- Zuordnung — Jedes Feature wird basierend auf der euklidischen Distanz (in projizierten Koordinaten) dem nächstgelegenen Zentroid zugeordnet.
- Aktualisierung — Zentroide werden als mittlere Position aller zugeordneten Features neu berechnet.
- Wiederholung bis die Zentroide konvergieren oder die maximale Anzahl an Iterationen erreicht ist.
Ausgeglichene Zonen
Die Methode Ausgeglichene Zonen verwendet einen genetischen Algorithmus, um optimale räumliche Gruppierungen zu finden:
- Eine anfängliche Population von Lösungen wird erstellt, wobei K-Means als Startpunkt verwendet wird, plus zufällige Variationen.
- Für jede Lösung wird ein Startpunkt (Seed) für jeden Cluster extrahiert und Zonen wachsen gelassen durch räumliche Nachbarn, um alle Features den Clustern zuzuweisen. Durch das Wachstum nicht zugewiesene Features werden dem kleinsten umliegenden Cluster zugewiesen. Die Rand-Features großer Cluster können dann kleineren Zonen neu zugewiesen werden.
- Jede Lösung wird anhand eines Fitness-Scores bewertet.
- Die besten Lösungen werden über mehrere Generationen hinweg kombiniert und mutiert, um das Ergebnis schrittweise zu verbessern.
- Der Algorithmus stoppt, wenn keine weitere Verbesserung gefunden wird oder die maximale Anzahl an Generationen erreicht ist.
Der Algorithmus verwendet räumliche Nachbarschaftsgraphen, um zusammenhängendes Zonenwachstum sicherzustellen — Features werden Zonen durch ihre räumlichen Nachbarn zugewiesen, was kompakte und verbundene Cluster fördert.
Fitness-Funktion:
Jede Lösungskandidat wird bewertet basierend auf:
- Größenvarianz — Wie gleichmäßig die Zonen dimensioniert sind (primäres Ziel).
- Kompaktheitsstrafe (optional) — Bestraft Zonen, bei denen der maximale Distanzschwellenwert überschritten wird.
Alle Einschränkungen (gleiche Größe, Kompaktheit) sind weiche Einschränkungen — der Algorithmus optimiert darauf hin, erzwingt sie jedoch nicht als harte Grenzen.
Algorithmus-Parameter:
| Parameter | Wert | Beschreibung |
|---|---|---|
| Populationsgröße | 40–50 | Anzahl der Lösungskandidaten pro Generation |
| Generationen | 40–50 | Maximale Anzahl an Evolutionszyklen |
| Mutationsrate | 0,1 | Wahrscheinlichkeit der Änderung des Cluster-Startpunkts |
| Crossover-Rate | 0,7 | Wahrscheinlichkeit der Kombination von Elternlösungen |
| Elitismus | Top 10% | Die besten Lösungen bleiben über Generationen erhalten |
Adaptive Parameter: Für größere Datensätze (>500 Features) werden die Populationsgröße und die Anzahl der Generationen automatisch reduziert, um angemessene Rechenzeiten beizubehalten.