Attribut-basiertes Styling
GOAT unterstützt attributbasiertes Styling, um die Visualisierung von Daten auf Karten zu verbessern. Dieser Ansatz erlaubt es der visuellen Darstellung, Variationen und Muster in den Daten widerzuspiegeln, wodurch es einfacher wird, komplexe räumliche Informationen zu verstehen.
Im Menü unterLayer Design sind Styling-Optionen für die ausgewählten Layer zu finden. Jeder Aspekt der Visualisierung eines Layers (Füllfarbe, Strichfarbe, Benutzerdefinierte Icon und Beschriftungen) kann individuell entsprechend einem Feld oder Attribut in den Daten des Layers gestaltet werden. Um das attributbasierte Styling für einen Layer zu aktivieren Klicken Sie auf Erweiterte Einstellungen 
![]()
Wenn Sie Ihre Styling-Einstellungen speichern und in weiteren Projekten verwenden möchten, können Sie dies durch Speichern als Standard tun.
Attribut auswählen
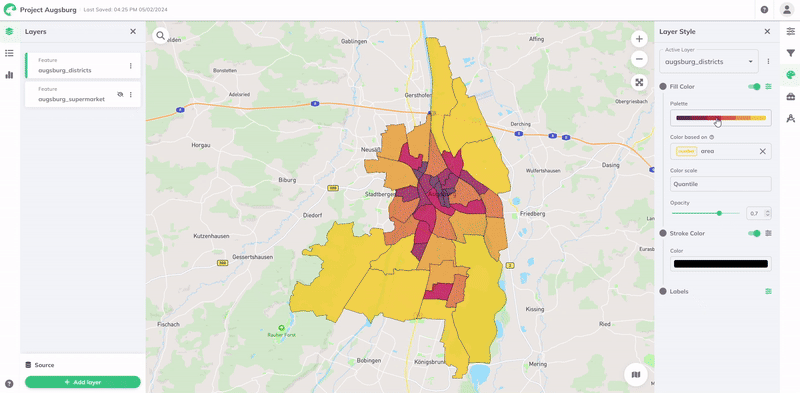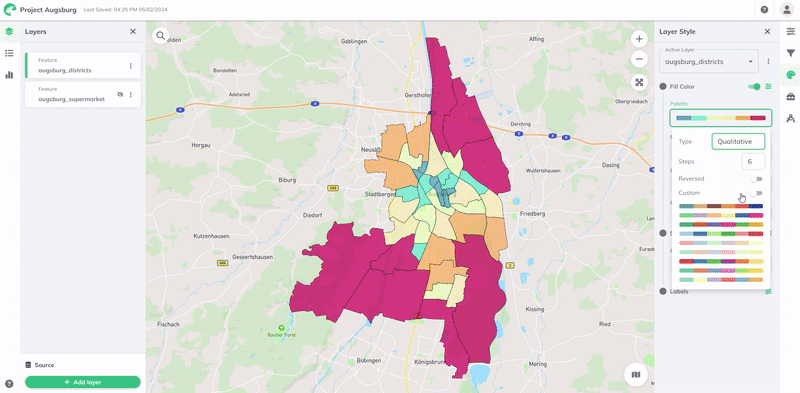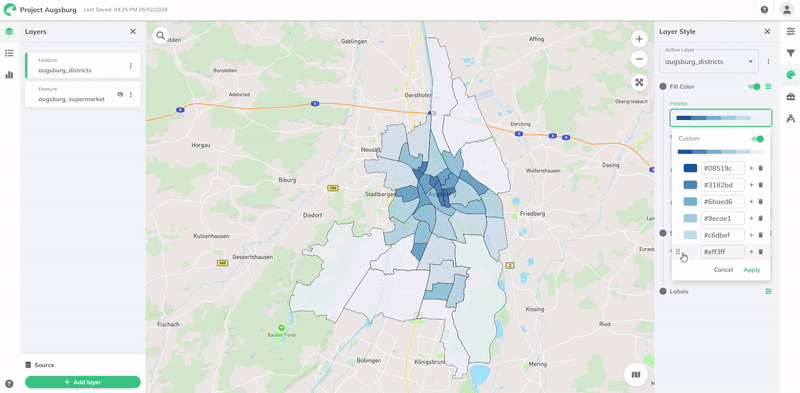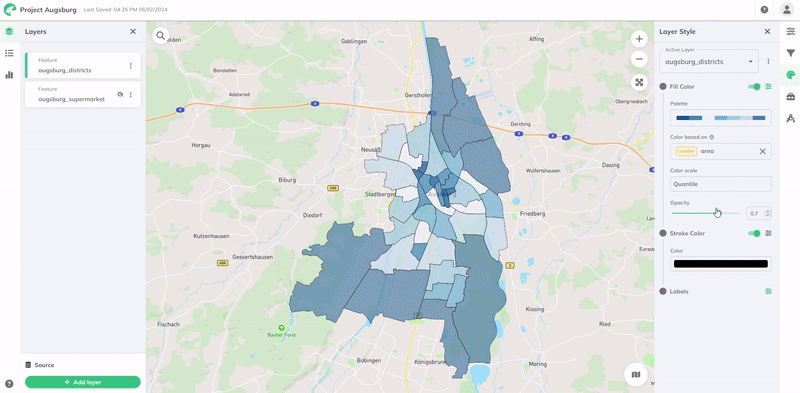
Um einen Stil basierend auf einem Attribut zu erstellen, wählen Sie es aus dem Dropdown-Menü des Feldes Farbe basierend auf aus. Daraufhin werden alle Attribute oder Spalten aufgelistet, die in den Daten Ihres Layers verfügbar sind.
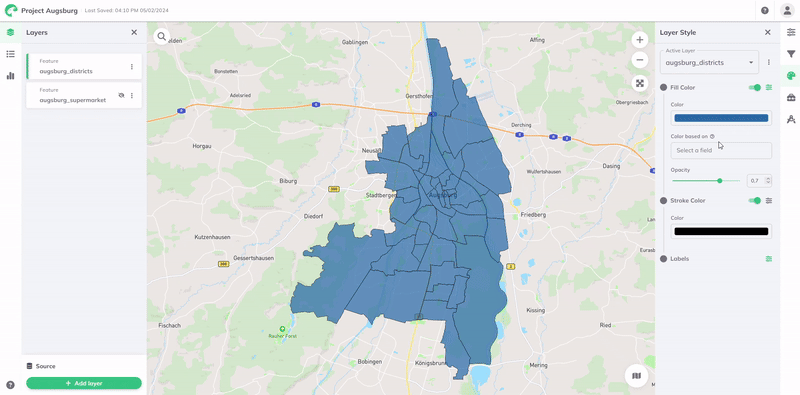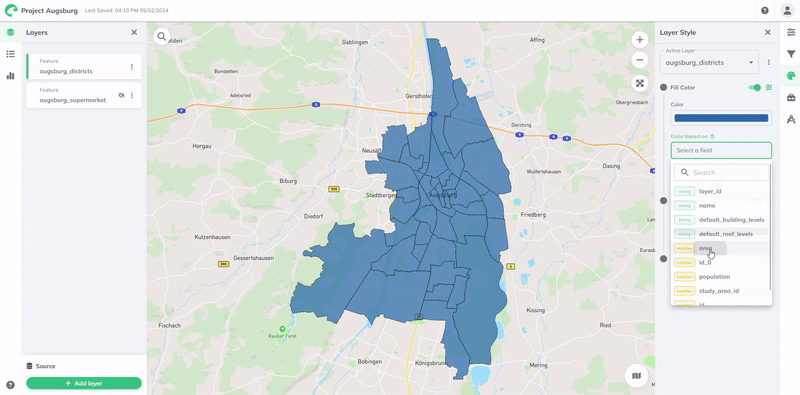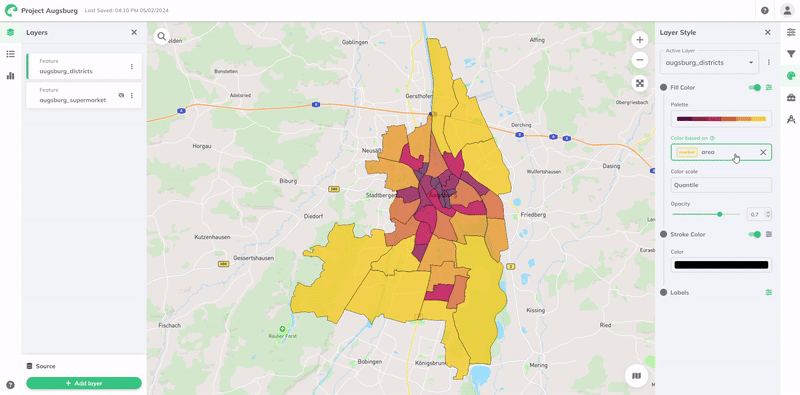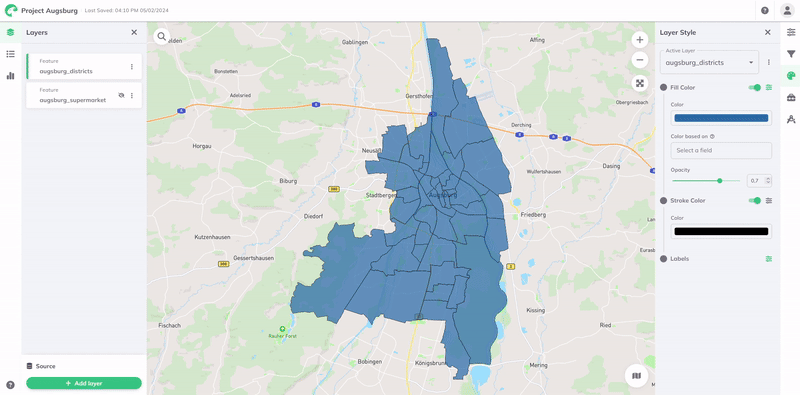
Die Visualisierung wird dann automatisch entsprechend dem Wertebereich der Daten gestaltet. Eine Farbpalette und eine Farbskala sind standardmäßig zugewiesen, können aber angepasst werden, um Ihren Daten und Visualisierungsanforderungen besser zu entsprechen. Die Farbskala verwendet eine Datenklassifizierungsmethode, um zu bestimmen, wie Datenwerte verschiedenen Farbkategorien zugewiesen werden.
Farbpalette
In diesem Abschnitt finden Sie GOATs umfassende Paletten, die alle für eine visuell eindrucksvolle räumliche Datendarstellung entwickelt wurden. Eine Palette ist eine Sammlung von Farben, die ausgewählt wurden, um die Skala der Werte oder Kategorien in den Daten Ihrer Layer darzustellen.
Für weitere Anpassungen können Sie einen anderen Typ der Palette, eine andere Anzahl von Schritten oder Umgekehrt der Farbreihenfolge wählen. Sie können auch eine benutzerdefinierte Farbpalette definieren, indem Sie die Benutzerdefiniert-Schaltfläche aktivieren.
GOAT bietet einen umfassenden Satz an vordefinierten Paletten, die in vier verschiedene Palettentypen unterteilt sind, um die Auswahl und Anwendung zu erleichtern.
| Palettentyp | Beispiel | Beschreibung |
|---|---|---|
| Divergierend |  | Diese Art von Farbpalette ist ideal für die Darstellung von Daten, die um einen kritischen Mittelpunkt zentriert sind oder eine natürliche Teilung aufweisen. Sie eignet sich besonders für die Darstellung von Daten, die sowohl positive als auch negative Abweichungen von einem zentralen Wert aufweisen, so dass diese Abweichungen klar und effektiv visualisiert werden können. |
| Sequentiell |  | Diese Farbpalette ist für Daten gedacht, die einem natürlichen Verlauf oder einer geordneten Abfolge folgen. Sie eignet sich hervorragend zur Visualisierung von kontinuierlichen Daten, bei denen die Werte entlang eines Spektrums entweder schrittweise ansteigen oder abfallen. Sie eignet sich daher besonders für die klare Darstellung von Daten, die sich allmählich von einem Extrem zum anderen verändern. |
| Qualitativ | | Diese Farbpalette ist für Daten gedacht, die in bestimmte, eindeutige Gruppen oder Klassen eingeteilt sind. Qualitative Farbpaletten sind so konzipiert, dass sie zwischen einzelnen Kategorien unterscheiden. Wichtig ist, dass diese Paletten dies tun, ohne eine inhärente Ordnung oder relative Bedeutung zwischen den verschiedenen Kategorien zu suggerieren. |
| Einzelner Farbton |  | Bei dieser Farbpalette handelt es sich um ein Farbschema, das in der Datenvisualisierung verwendet wird und verschiedene Farbtöne, Schattierungen und Nuancen einer einzigen Farbe verwendet. Dieser Ansatz schafft eine visuell kohärente und harmonische Ästhetik, die besonders effektiv sein kann, um Informationen ohne die Ablenkung durch mehrere Farben zu vermitteln. |
Farbskala
Unter Palette finden Sie die Farbe basierend auf und die Farbskala, die Datenwerte mit einem Farbspektrum verbindet. Sie wandelt einen gegebenen Datenwert innerhalb eines gegebenen Bereichs in eine entsprechende Farbe aus einem gegebenen Farbspektrum um. GOAT bietet sechs vordefinierte Datenklassifizierungsmethoden: Quantil, Standardabweichung, Gleiches Intervall, Heads und Tails, Benutzerdefinierte Schritte, und Benutzerdefinierte Ordinalskala.
Datenklassifizierungsmethoden
Quantil
Die Quantil-Klassifizierung unterteilt Daten in Gruppen mit einer gleichen Anzahl von Werten in jeder Klasse, basierend auf ihren Attributwerten. Diese Methode ist nützlich für die Analyse und Visualisierung von Mustern in Daten und kann dabei helfen, Trends und Muster zu erkennen, die vielleicht nicht so leicht zu erkennen sind. Die Tatsache, dass die Datenwerte in jeder Klasse in gleichen Mengen gruppiert werden, macht diesen Ansatz ideal für Daten, die linear verteilt sind. Standardmäßig werden die Daten in 7 Klassen aufgeteilt.
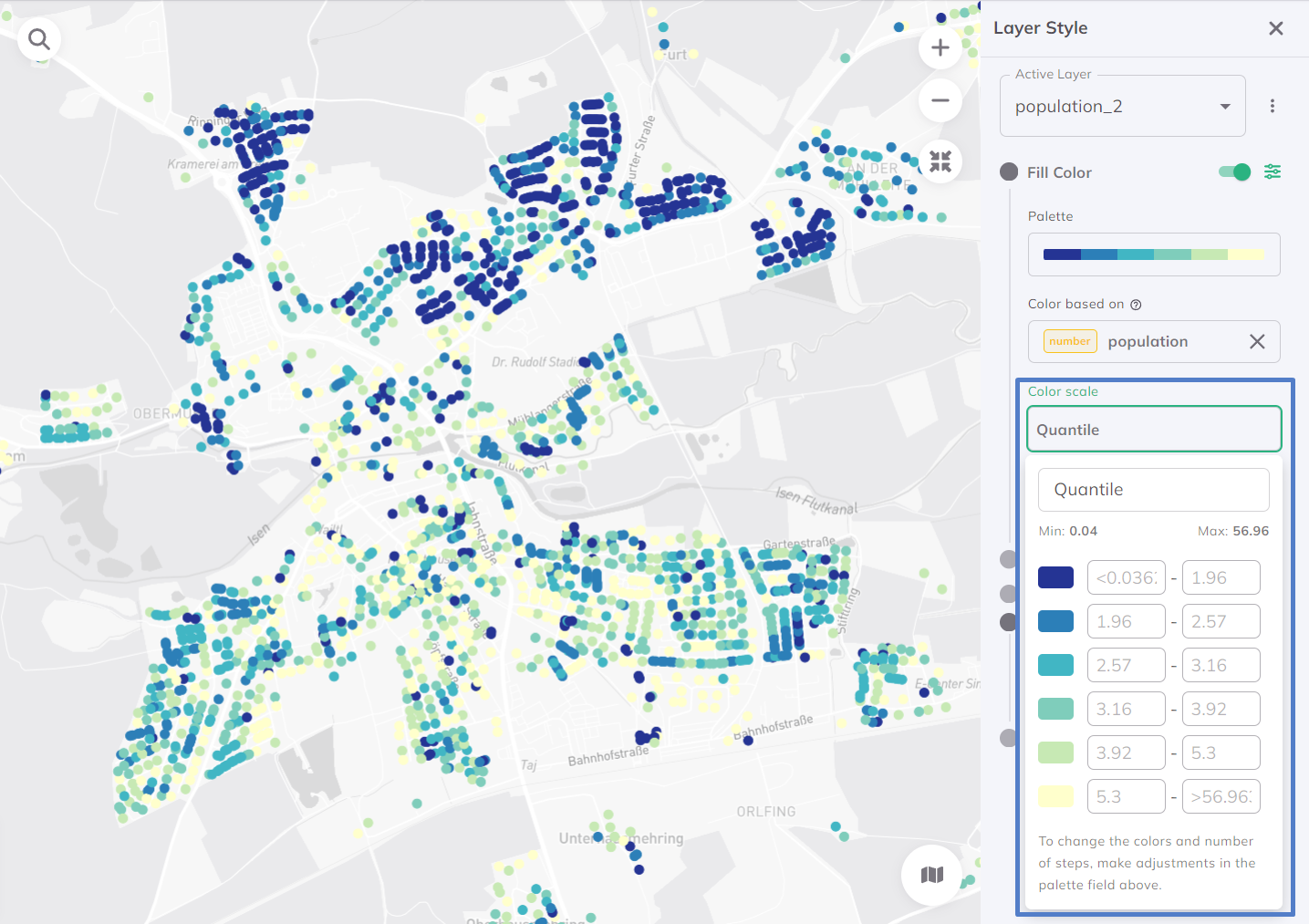
Möchten Sie besser verstehen, was eine Quantilklassifizierung ist? Schauen Sie in unser Glossar.
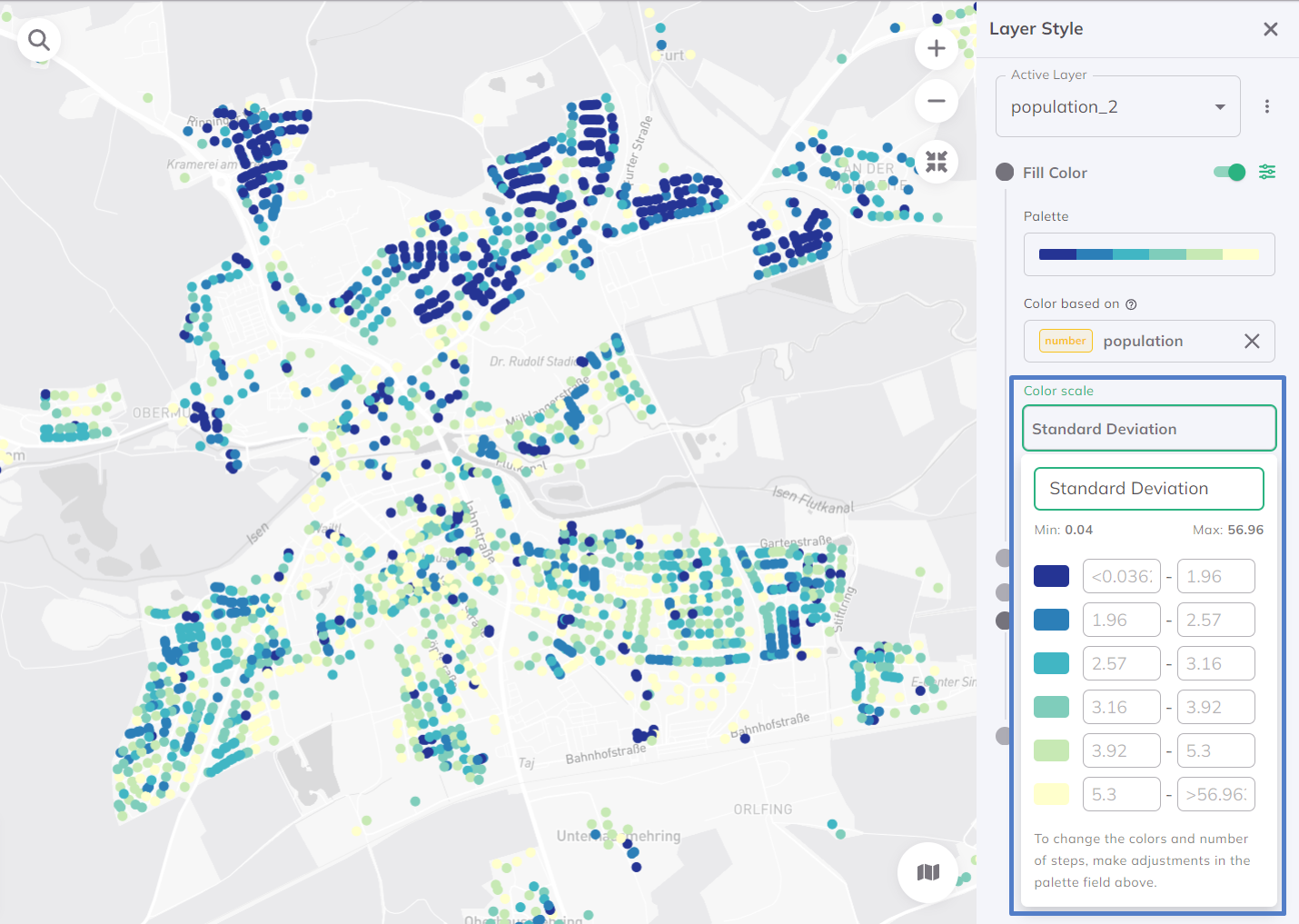
Standardabweichung
Die Methode der Standardabweichung ist ein statistischer Ansatz, der in der Datenvisualisierung verwendet wird. Sie verwendet das Konzept der Standardabweichung, ein Maß für das Ausmaß der Variation oder Streuung in einer Gruppe von Werten, um zu bestimmen, wie Datenpunkte verschiedenen Farbkategorien zugeordnet werden. Diese Methode ist wertvoll, da sie eine statistische Perspektive auf die Daten bietet und es den Benutzern ermöglicht, die relative Streuung und Verteilung der Werte innerhalb des Datensatzes schnell zu erfassen. Standardmäßig werden die Daten in 7 Klassen aufgeteilt.
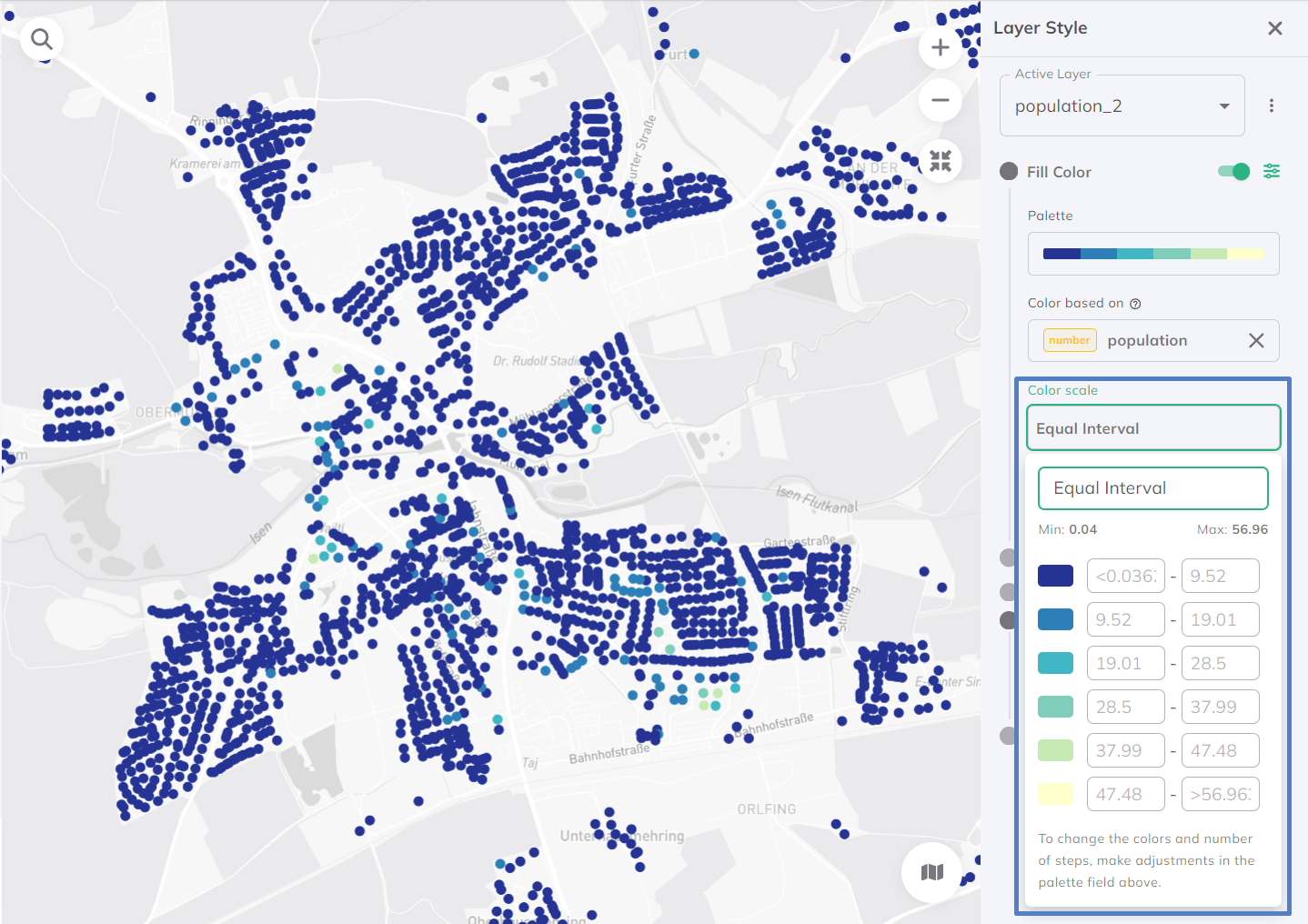
Gleiches Intervall
Bei der Klassifizierung „Gleiches Intervall“ wird der Bereich der Attributwerte in gleiche Intervallklassen unterteilt. Standardmäßig werden die Daten in 7 Klassen aufgeteilt.
Heads und Tails
Die Heads und Tails-Methode wird für Datensätze mit einer schiefen Verteilung verwendet. Sie wurde entwickelt, um die Extreme in den Daten hervorzuheben, indem sie sich auf die 'Heads' (die sehr hohen Werte) und die 'Tails' (die sehr niedrigen Werte) konzentriert. Diese Methode ist besonders nützlich für Datensätze, bei denen die wichtigsten Informationen in den Extremen zu finden sind, und bei denen die Hervorhebung dieser Werte zu einem besseren Einblick und Verständnis führen kann. Standardmäßig werden die Daten in 7 Klassen aufgeteilt.
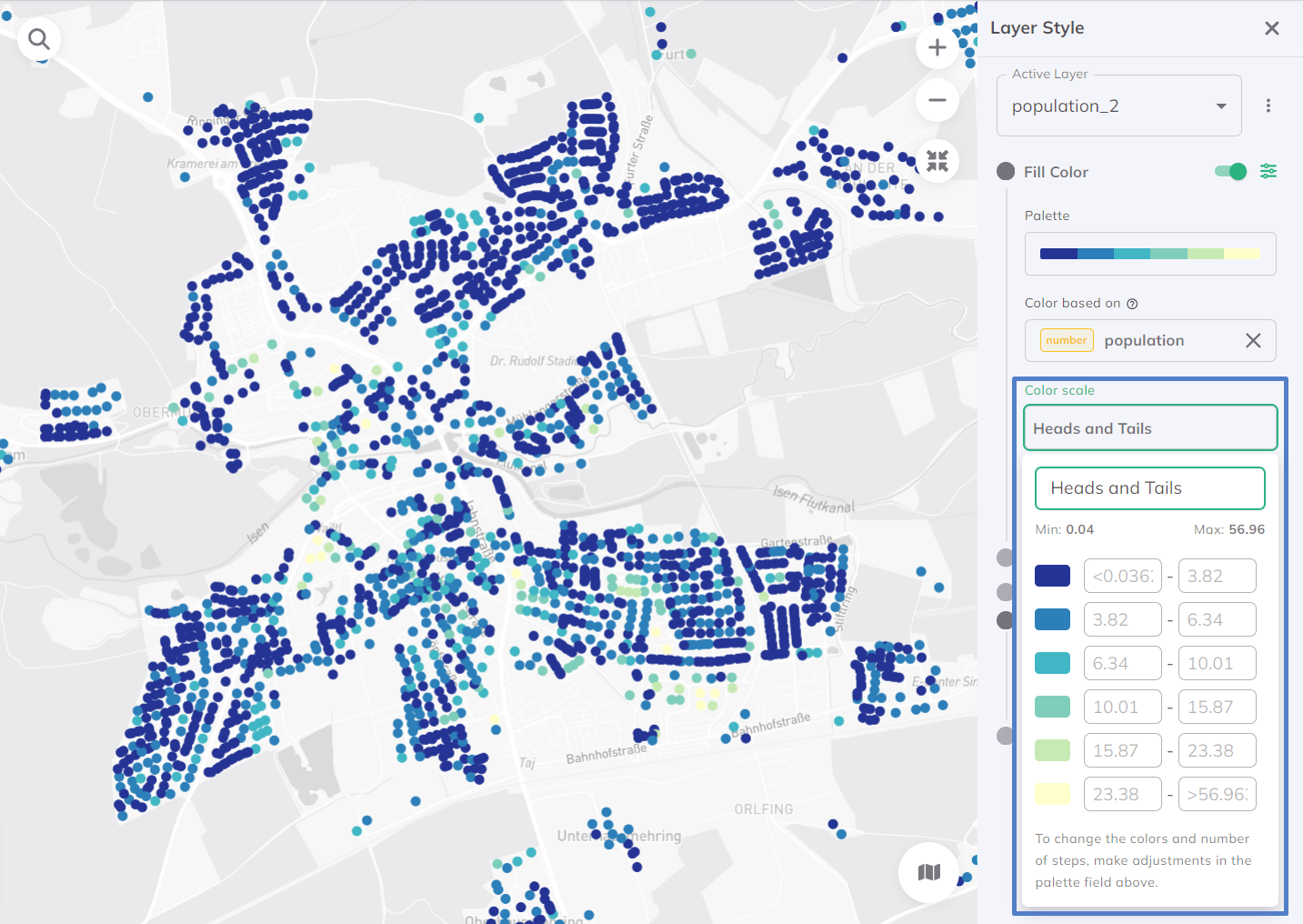
Benutzerdefinierte Schritte (für Zahlen)
Die Klassifizierung Benutzerdefinierte Schritte ist eine Datenvisualisierungsmethode für numerische Daten. Sie ermöglicht die Definition von benutzerdefinierten Zwischenpunkten oder Schwellenwerten und bietet damit einen maßgeschneiderten Ansatz für kontextspezifische Visualisierungen.
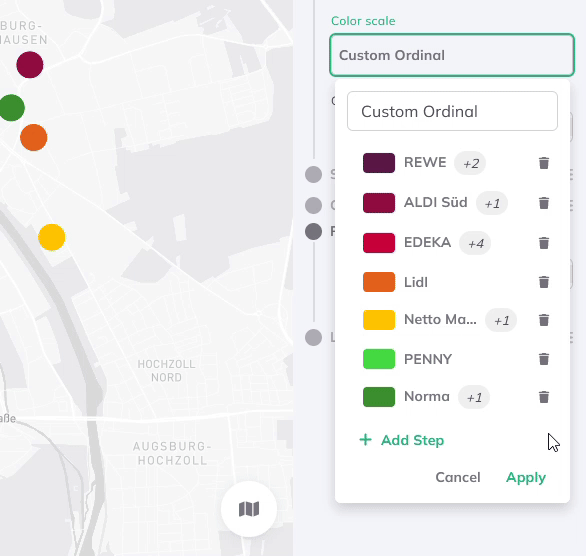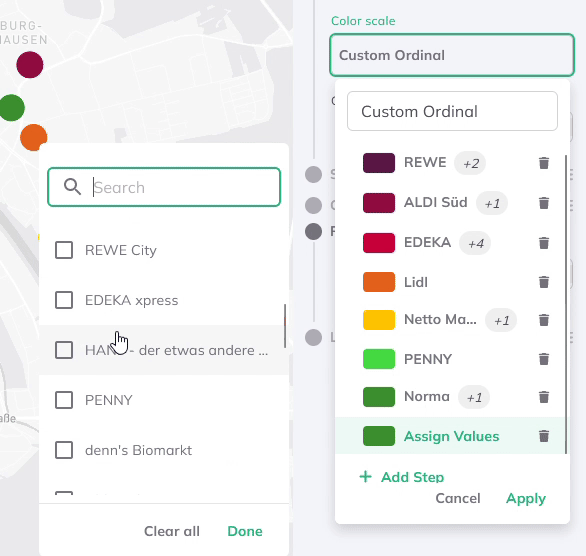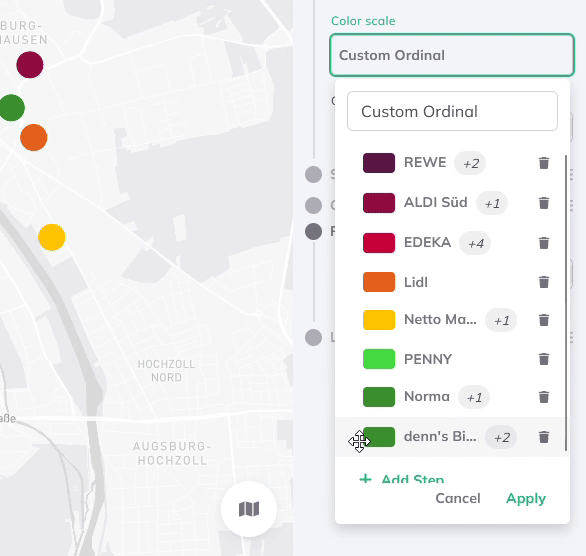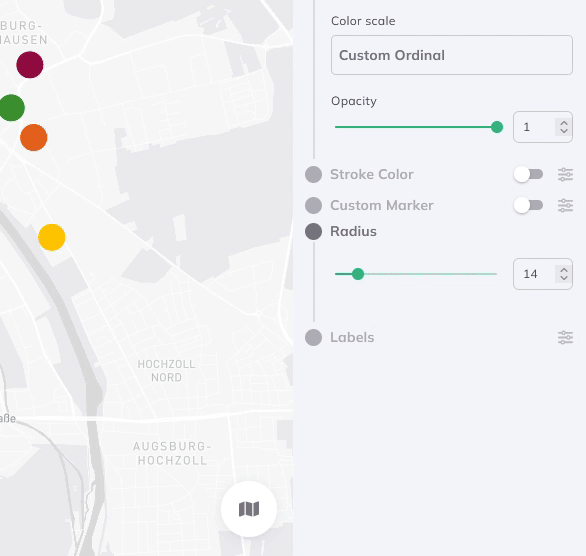
Benutzerdefinierte Ordinalskala (für Zeichen)
Die benutzerdefinierte Ordinalskala ist eine Methode zur Datensortierung und -visualisierung, die auf Zeichen-Daten angewendet wird, wie z. B. Kategorien, Etiketten oder textbasierte Variablen. Im Gegensatz zu numerischen Daten, bei denen die Reihenfolge typischerweise auf der Größe basiert, fehlt bei Textdaten oft eine natürliche Reihenfolge. Die Benutzerdefinierte Ordinalskala ermöglicht es daher, eigene Ordnungsregeln für Textfelder zu definieren und eine individuelle, auf die eigenen Bedürfnisse zugeschnittene Reihenfolge zu erstellen.
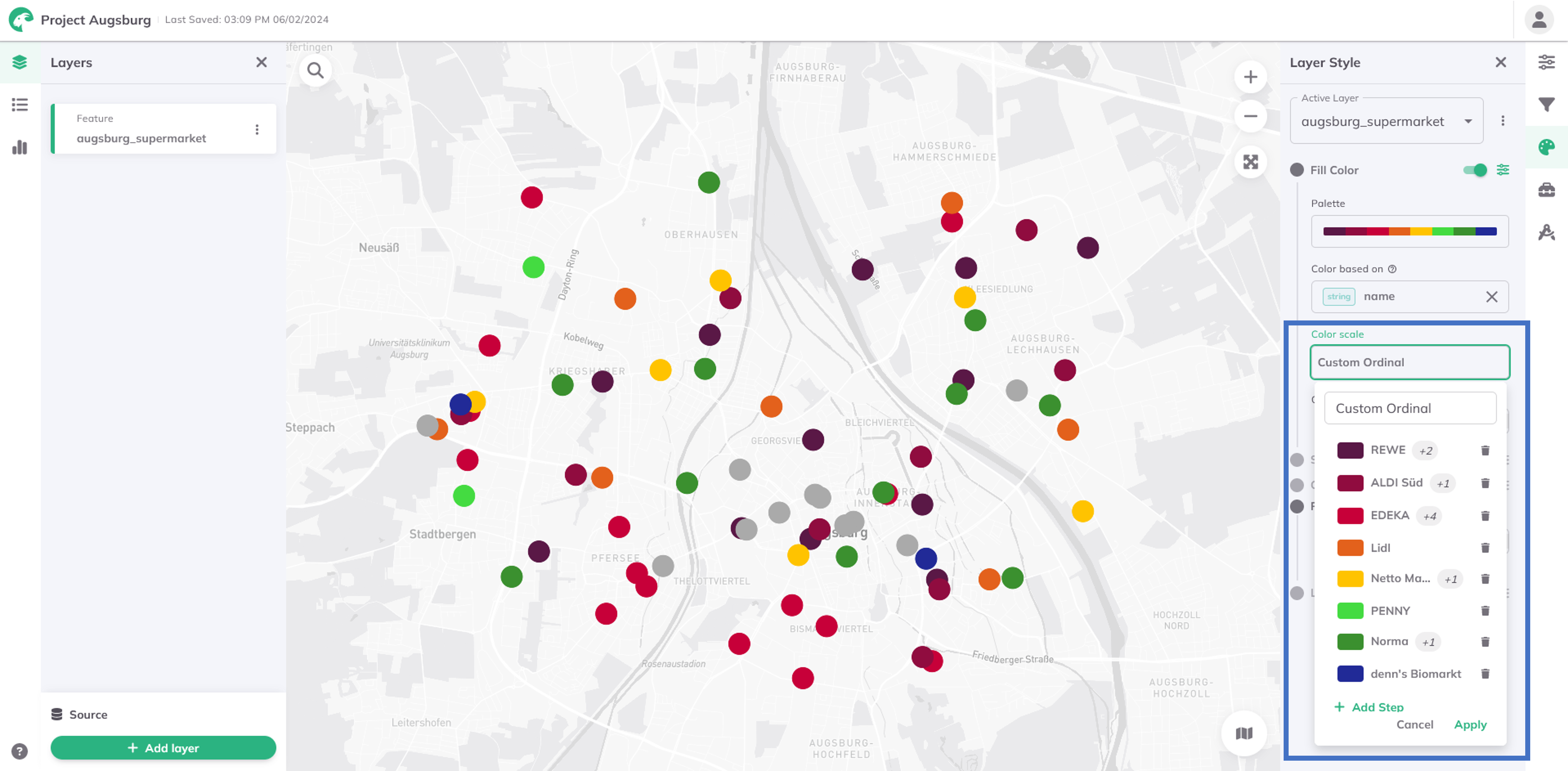
So können zusätzliche Schritte hinzugefügt und mehrere Text-Werte pro Gruppe aus einem Dropdown-Menü ausgewählt werden. Das Dropdown-Menü listet dabei alle Attributwerte des Datensatzes auf.
Layer Design
- Füllfarbe
- Strichfarbe
- Benutzerdefinierter Icon
Layer aus. GOAT wendet eine zufällige Farbpalette auf Ihre Ergebnisse an.
Layer. GOAT wendet eine zufällige Farbpalette auf Ihre Ergebnisse an.